
5.2. Неравномерные эффективные коды
Неравномерные блочные воды используются практически только для кодирования источников для устранения или уменьшения избыточности, вызванной тем, что передаваемые сообщения не равновероятны. Как отмечалось в § 4.3, идея такого кодирования заключается в том, что более вероятные сообщения кодируются короткими блоками, а менее вероятные - длинными, в результате чего средняя длина блока уменьшается.
При построении неравномерного кода необходимо обеспечить однозначность декодирования. Поясним это простым примером. Пусть алфавит источника содержит шесть сообщений, которые обозначим А, Б, В, Г, Д, Е, передаваемых независимо друг от друга с вероятностями Р(А) =0,4; Р(Б) = 0,3; Р(В) = 0,1; Р(Г) = 0,08; Р(Д) = 0,07; Р(Е) = 0,05. Сумма этих вероятностей, конечно, равна 1. Заметим, что энтропия этого источника
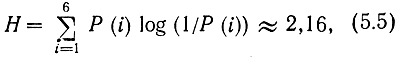
где i = 1, ..., 6 - номер сообщения в алфавите источника.
Чтобы закодировать эти сообщения равномерным двоичным кодом, нужно затратить на каждое сообщение три символа. В соответствии с теоремой кодирования для источника (см. § 4.3) эти сообщения можно закодировать двоичными символами так, чтобы в среднем на каждое сообщение затрачивать nср = 2,16+ε двоичных символов, где ε - сколь угодно малое положительное число. Попробуем сделать это, не задумываясь над однозначностью декодирования, попросту присваивая наиболее вероятным символам наиболее короткие блоки, например:
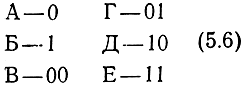
Таким образом, для передачи сообщений А и В, имеющих суммарную вероятность 0,7, используют один символ, а для передачи остальных сообщений, имеющих суммарную вероятность 0,3, - два символа, так что среднее число символов на сообщение
Получилось, что сообщения закодированы еще более экономно, чем позволяет теорема кодирования. Но это объясняется тем, что выбранный код не пригоден для передачи сообщения, так как он не обеспечивает однозначного декодирования. Действительно, пусть принята такая последовательность символов:
Ее можно в соответствии с (5.6) декодировать так:
и еще множеством различных способов.
Конечно, можно при коде (5.6) обеспечить однозначность декодирования, если после каждого сообщения передавать некоторый символ ("запятую"), разделяющую сообщения. Но тогда это уже будет не двоичный код, а троичный. Так поступил Морзе, создавая свой код, где кроме точки и тире использовал третий символ - "пробел".
Однако можно построить и однозначно декодируемые двоичные коды "без запятой". Для этого достаточно (хотя и не необходимо) строить код так, чтобы он удовлетворял так называемому "префиксному свойству". Оно заключается в том, что ни одно используемое кодовое слово не должно совпадать с началом ("префиксом") другого кодового слова. Это свойство не выполнено у кода (5.6), так как, например, слово, соответствующее сообщению А, является началом слова, соответствующего сообщению В и т. д.
Существует несколько алгоритмов построения неравномерных кодов с префиксным свойством. Среди них оптимальным, т. е. позволяющим лучше всего приблизиться к границе, определяемой энтропией, является алгоритм Хафмена. Рассмотрим здесь более простой алгоритм Фено, в большинстве случаев приводящий к тем же результатам.
Алгоритм Фено заключается в следующем. Сообщения алфавита источника, записанные в порядке невозрастающих вероятностей, разделяются на две части так, чтобы суммарные вероятности сообщений в каждой из этих частей были по возможности почти одинаковыми. Сообщениям первой части приписывается в качестве первого символа 0, а сообщениям второй части- 1. Затем каждая из этих частей (если она содержит более одного сообщения) делится на две, по возможности равновероятные, части и в качестве второго символа для первой из них берется 0, а для второй - 1. Этот процесс повторяется, пока в каждой из полученных частей не останется по одному сообщению.
Для примера (5.6) на первом этапе разделения в первой части окажется одно сообщение А с вероятностью 0,4, а во второй части - остальные сообщения с суммарной вероятностью 0,6. Если бы включить в первую часть два сообщения (А и Б), то отклонение от равновероятности было бы еще больше. Припишем сообщению А символ 0, а остальным сообщениям, в качестве первого символа - 1.
На втором этапе разделим сообщения Б, В, Г, Д, Е на две равновероятные части, включив в первую часть сообщение Б, а во вторую часть - В, Г, Д, Е. Здесь суммарные вероятности для обеих частей одинаковы - по 0,3. Припишем сообщению Б в качестве второго символа 0, а остальным сообщениям - 1. На третьем этапе сообщения В и Г образуют одну часть, а сообщения Д и Е - вторую и т. д. В результате приходим к такому коду:
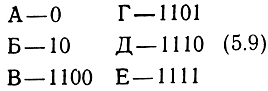
Этот код, как можно убедиться, по своему построению обладает префиксным свойством. Поэтому, например, последовательность символов (5.8) декодируется однозначно, а именно:
Среднее число символов на одно сообщение с учетом их вероятностей равно 2,2, т. е. превышает энтропию (5.5) менее, чем на 2%. Еще ближе можно было бы подойти к энтропии, если при составлении кода сопоставлять с кодовыми словами не одиночные сообщения, а последовательности из нескольких сообщений.
Следует еще раз подчеркнуть, что эффективные неравномерные коды позволяют сократить только ту избыточность источника, которая вызвана неравной вероятностью сообщений. В большинстве случаев основную роль играет избыточность другого происхождения, связанная с зависимостью между элементами сообщений. Для ее сокращения применяют другие методы, описанные в § 4.3.

При использовании материалов сайта активной гиперссылки обязательна:
http://rateli.ru/ 'Радиотехника'