
5.3. Принципы помехоустойчивого кодирования
Покажем, каким образом избыточное кодирование позволяет повысить верность передачи сообщения. Как отмечалось, для помехоустойчивых блочных равномерных кодов mn>М. Это значит, -что для передачи знаков сообщения используют лишь часть возможных последовательностей, составленных из m-ичных символов (часть пространства n-последовательностей). Последовательности, используемые при кодировании, называются разрешенными кодовыми комбинациями, а все другие "-последовательности - запрещенными. На вход канала поступают только разрешенные "комбинации. Если при передаче кодовой комбинации bi помехи не вызовут ошибок, то на выходе канала возникает та же разрешенная комбинация. Если же один или несколько символов принимается ошибочно, то на выходе канала может возникнуть одна из запрещенных комбинаций.
Таким образом, если комбинация на выходе канала оказывается запрещенной, то это указывает на то, что при передаче возникла ошибка. Отсюда видно, что избыточный код позволяет обнаружить, в каких принятых кодовых комбинациях имеются ошибочные символы. Безусловно, не все ошибки могут быть обнаружены. Существует вероятность того, что, несмотря на возникшие ошибки, принятая последовательность кодовых символов окажется разрешенной комбинацией (но не той, которая передавалась). Однако при разумном выборе кода вероятность необнаруженной ошибки (т. е. ошибки, которая переводит разрешенную комбинацию в другую разрешенную комбинацию) может быть сделана очень малой.
Если принята запрещенная кодовая комбинация bj, то, зная параметры канала, можно определить, какая из разрешенных комбинаций bi вероятнее всего передавалась, и произвести декодирование принятой комбинации bj в комбинацию, совпадающую с bj. Если действительно передавалась bi, то тем самым возникшие ошибки будут исправлены. Конечно, возможны случаи, когда в действительности передавалась не наиболее вероятная комбинация bi, а какая-то другая, так что декодирование окажется неправильным. Тем не менее при достаточной избыточности кода и хорошей его структуре вероятность неисправленной ошибки может быть достаточно малой и во всяком случае значительно меньшей, чем при примитивном кодировании.
Из сказанного видно, что при избыточном кодировании возможны два основных метода декодирования - с обнаружением ошибок и с их исправлением*. Сущность метода декодирования с исправлением ошибок заключается в том, что все множество В принимаемых последовательностей длины n разбивается на М не перекрывающихся подмножеств: В1 В2,...., ВМ. Если принята последовательность, принадлежащая подмножеству Вi, то считается, что передавалась кодовая комбинация bi. Естественно, что в подмножестве Вi следует включить те запрещенные комбинации bj, при приеме которых наиболее вероятной переданной комбинацией является bi.
* (Иногда говорят, что помехоустойчивые коды подразделяют на коды, обнаруживающие ошибки, и коды, исправляющие их. Такое разделение необоснованно, поскольку один и тот же код можно использовать при обоих методах декодирования.)
При декодировании с обнаружением ошибок множество В разбивается на М+1 подмножеств, из которых В1, В2, ..., BM содержат каждое по одной (разрешенной) кодовой комбинации, а подмножество BM+1 - все остальные (запрещенные) комбинации. В некоторых системах связи принятая запрещенная комбинация просто отбрасывается и не поступает к получателю. Это обосновано в тех случаях, когда потеря переданного сообщения значительно менее вредна, чем получение ложного сообщения. Чаще при декодировании с обнаружением ошибки ошибочно принятая кодовая комбинация не теряется, а восстанавливается специальными методами. Среди них наиболее распространен метод переспроса (см. § 5.7).
Необходимо отметить, что правило декодирования с обнаружением ошибок однозначно определяется кодом (т. е. выбором разрешенных комбинаций) и не зависит от свойств канала. При исправлении ошибок, наоборот, возможны различные правила декодирования, поскольку каждую из запрещенных комбинаций можно включить в любое из подмножеств Вi. В зависимости от свойств канала то или иное правило является предпочтительным.
Существуют и смешанные методы декодирования, когда некоторые ошибки исправляют, а другие только обнаруживают. Здесь множество В также разбито на М+1 подмножеств, но в подмножество В1 ,..., ВМ помимо разрешенных комбинаций входят и некоторые близкие к ним запрещенные (исправляемые), а в ВМ+1 - только те запрещенные комбинации, которые не могут быть достаточно надежно исправлены.
Говорят, что в канале произошла ошибка кратности q, если в кодовой комбинации q символов приняты ошибочно. Легко видеть, что кратность ошибки есть не что иное, как расстояние Хэмминга между переданной и принятой кодовыми комбинациями, или, иначе, вес вектора ошибки (см. с. 64).
Рассматривая все разрешенные кодовые комбинации и определяя кодовые расстояния между каждой парой, можно найти наименьшее из "их d = min d(i; j), где минимум берется по всем парам разрешенных комбинаций. Это минимальное кодовое расстояние является важным параметром кода. Очевидно, что для простого кода d = 1.
Обнаруживающая способность кода характеризуется следующей теоремой.
Если код имеет d>1 и используется декодирование по методу обнаружения ошибок, то все ошибки кратностью q<d обнаруживаются. Что же касается ошибок кратностью q^d, то одни из них обнаруживаются, а другие нет.
Для доказательства достаточно вспомнить, что кодовое расстояние между посланной и принятой комбинациями равно q. Следовательно, если q≥d, принятая комбинация не может быть разрешенной, так как это противоречило бы определению d. Поэтому она будет принадлежать подмножеству запрещенных комбинаций, т. е. ошибка будет обнаружена. При q<d принятая комбинация может оказаться разрешенной и ошибка останется не обнаруженной, но часто и в этом случае принятая комбинация оказывается запрещенной и ошибка обнаруживается.
Процесс исправления ошибок рассмотрим сначала для симметричного канала без памяти. В таком канале, описанном в § 3.4 по определению, вероятность правильного приема символа 1-р не зависит от того, какой символ передается, а также от того, как приняты остальные символы. Вероятность того, что вместо переданного символа bi будет принят символ b̂j{j≠i) равна р/(m-1). Отсюда легко вывести, что вероятность получения на
выходе канала комбинации b̂j если "а вход подана комбинация bi
Это следует непосредственно из теоремы умножения вероятностей независимых событий и из того, что для перехода bi в b̂j необходимо, чтобы на определенных d(i; j) разрядах произошли определенные ошибки, а на остальных разрядах символы были приняты верно.
Таким образом, в симметричном канале без памяти P(b̂j|bi) зависит только от кодового расстояния между bi и bj. В случаях, когда р<(m-1)/m, что практически всегда выполняется, выражение (5.5) монотонно убывает с увеличением d(i; j). Следовательно, вероятность принять комбинацию bj тем больше, чем меньше ее кодовое расстояние от переданной комбинации bi.
Задачей декодера является принятие решения о том, какая кодовая комбинация передавалась, если принята комбинация bj. Разумеется, решение, принимаемое декодером, не всегда верное. Однако можно добиваться минимума вероятности ошибочного декодирования. Пусть P(bi|bj)-условная вероятность того, что передавалась комбинация bi, если принята комбинация bj. Эту условную вероятность называют апостериорной вероятностью в отличие от безусловной априорной вероятности Р(bi) того, что передается bi, когда ничего еще не известно о принятой комбинации. Предположим, что декодер по принятой комбинации bj решил, что передавалась комбинация bk. Вероятность того, что это решение верно, очевидно, равна P(bk|bj). Чтобы эта вероятность была максимально возможной, декодер должен из всех разрешенных комбинаций bi(i= 1, ..., М) выбрать ту, для которой апостериорная вероятность максимальна. Это правило декодирования по максимуму апостериорной вероятности можно записать сокращенно так:
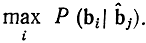
Из теории вероятностей известно, что
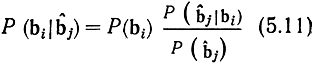
(формула Байеса).
Если, как часто бывает на практике, все разрешенные кодовые комбинации равновероятны (Р (bi) = const = 1/М), то из (5.11) следует, что максимум апостериорной вероятности совпадает с максимум условной вероятности P(bj|bi), которую называют функцией правдоподобия*. Правило декодирования по максимуму правдоподобия можно сокращенно записать так:
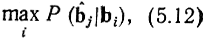
а эта вероятность, как видно, в симметричном канале без памяти определяете только кодовым расстоянием между bi и bj. Следовательно, в таком канале запрещенную комбинацию bj следует декодировав, как ту разрешенную комбинацию bi, которая находится на наименьшем расстоянии от bj. Иначе говоря, в подмножество Вi следует включить все те комбинации bj, которые ближе (в смысле Хэмминга) к bi, чем в любой другой разрешенной комбинации.
* (Более подробно о правилах статистического решения сказано в гл. 6.)
Такое декодирование по наименьшему расстоянию* является оптимальным для симметричного канала без памяти. Однако для других каналов это правило может и не быть оптимальным, т. е. не соответствовать максимуму правдоподобия.
* (Это правило декодирования называют также алгоритмом Хэмминга.)
Исправляющая способность кода при этом правиле декодирования определяется следующей теоремой.
Если код имеет d>2 и используется декодирование с исправлением ошибок по наименьшему расстоянию, то все ошибки кратностью q<d/2 исправляются*. Что же касается ошибок большей кратности, то одни из них исправляются, а другие нет.
* (Подчеркнем, что здесь имеется в виду строгое 'неравенство, т. е. случай q=d/2 исключается.)
Для доказательства покажем, что в условиях теоремы (при q<d/2) действительно переданная комбинация bi ближе (в смысле
Хэмминга) к принятой комбинации bj, нежели любая другая разрешенная комбинация. Предположим противное, т. е. что существует разрешенная комбинация bk, для которой d(k; j)<d(i; j). На основании (2.95) отсюда следует, что d(k; i)≤d(k; j) + d(i; j)<2d(i; j). Но по условию теоремы d(i; j)=q<d/2. Отсюда d(k; i)<d, что противоречит определению d. Это противоречие и свидетельствует о справедливости теоремы.
Полученные результаты можно выразить следующими формулами:
где q0 - кратность гарантированно обнаруживаемых ошибок в режиме, когда ошибки только обнаруживаются; qu - кратность гарантированно исправляемых ошибок.
Две доказанные теоремы позволяют оценить вероятность ошибочного декодирования (при декодировании с исправлением ошибок) и вероятность необнаруженной ошибки (при декодировании с обнаружением ошибок) в симметричном канале без памяти. Для этого напомним, что вероятность возникновения каких-либо ошибок кратности q определяется известным биномиальным законом
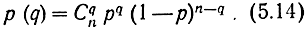
Эта формула следует из того, что ошибки в таком канале являются независимыми событиями с вероятностью р.
Используя доказанные теоремы и равенство (5.1 следующие оценки для вероятности ошибочного декодирования pо.д при коррекции ошибок и для вероятности не обнаруженной ошибки рн.о при обнаружении ошибок:
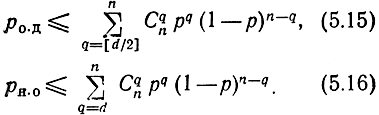
Здесь [d/2] обозначает наибольшую целую часть d/2. Знак неравенства в (5.8) и (5.9) ставится потому, что код, вообще говоря, может исправлять некоторые ошибки кратности d/2 и выше и обнаруживать ошибки кратности d и выше.
Помехоустойчивые коды можно применять и в дискретных каналах со стиранием (см. § 3.4). Если в принятом блоке ошибок нет, но имеется qc стертых (не опознанных модемом) символов, то при qc<d эти стирания могут быть исправлены при декодировании по минимуму расстояния. Это вытекает из определения d, так как для того, чтобы две комбинации оказались неразличимыми, необходимо стереть не менее d символов. Можно показать также, что при декодировании по минимуму расстояния в канале с ошибками и стираниями гарантированно исправляются q0 ошибок и qc стираний, если qc+2q0<d.
Неравенства (5.15) и (5.16) иллюстрируют важную роль d как основного показателя исправляющих и обнаруживающих свойств кода в симметричном канале без памяти (чем больше d, тем меньше po.д и рн.o). Поэтому задача кодирования состоит в выборе кода, обладающего максимально достижимым d. Впрочем, такая формулировка задачи неполна. Увеличивая длину кода п II сохраняя число кодовых комбинаций М, можно получить сколь угодно большое значение d. Проще всего это достигается повторением символов кодовых комбинаций. Но совершенно очевидно, что такое "решение" задачи не представляет интереса, так как с увеличением п уменьшается возможная скорость передачи информации от источника. Если длина кода п задана, то можно получить любое значение d, не превышающее n, уменьшая число комбинаций М. Поэтому задачу поиска наилучшего кода (в смысле максимального d) следует формулировать так: при заданных М и n найти код длины n, содержащий М комбинаций и имеющий наибольшей возможное d. В общем виде эта задача в теории кодирования не решена, хотя для многих значений n и М ее решения получены.
Эффективность помехоустойчивого кода возрастает при увеличении его длины. Это вытекает из (4.58), так как вероятность ошибочного декодирования уменьшается при увеличении длины кодируемого сообщения.
На первый взгляд помехоустойчивое кодирование реализуется весьма просто. В память кодирующего устройства (кодера) записываются разрешенные кодовые комбинации выбранного кода и правило, по которому с каждым из М сообщений источника сопоставляется одна из таких комбинаций. Данное правило известно и на декодере.
Получив от источника определенное сообщение, кодер отыскивает соответствующую ему комбинацию и посылает га канал. В свою очередь, декодер, приняв комбинацию, искаженную помехами, сравнивает ее со всеми М комбинациями списка и отыскивает ту из них, которая ближе остальных к принятой*. Однако даже при умеренных значениях n такой способ весьма сложный. Покажем это на примере.
* (Из этого видно, что операция декодирования значительно сложнее операции кодирования. Сказанное справедливо для всех кодов при декодировании с исправлением ошибок. )
Пусть для двоичного 'Кода выбрано значение n = 100, а скорость кода (log M)/n примем равной 0,5. Тогда log = 50 и М = 250≈1015. Таким образом, кодовая таблица должна содержать 1015 кодовых комбинаций, или 100 × 1015 = 1017 кодовых символов. В аппаратуре кодера и декодера эти таблицы "записываются" на двоичных запоминающих ячейках: например, магнитных дисках, магнитной ленте, триггерах, криотронах и т. п. Предположим, что в результате успехов микроэлектроники через несколько лет удастся производить подобную запись, затрачивая на каждый двоичный символ объем в 10-5 мм или 10-8 см3. Такие запоминающие устройства в настоящее время можно найти только на страницах фантастических романов. Вся таблица в данном случае займет объем 1017 × 10-8 = 109 см3. Это объем куба, каждая сторона которого равна 10 м. Очевидно, что изготовление такого устройства совершенно нереально*. Но им не исчерпываются кодер и декодер. В частности, в декодере необходимо проделать 1017 операций, сравнивая символы принятой комбинации с символами, хранящимися в таблице. Так как на это можно отвести только время порядка длительности кодовой комбинации (например, 1 с), а число операций, выполняемых в одну секунду электронными логическими схемами, не превышает в настоящее время 106-107, то пришлось бы применить около 1010 параллельно работающих схем сравнения.
* (Заметим, что число нейронов в нервной системе человеческого мозга по современным оценкам составляет "всего" около 1010.)
Таким образом, применение достаточно эффективных (а значит, - и достаточно длинных) кодов при табличном методе кодирования и декодирования технически невозможно. Поэтому основное направление теории помехоустойчивого кодирования заключается в поисках таких классов кодов, для которых кодирование и декодирование осуществляются не перебором таблицы, а с помощью некоторых регулярных правил, определенных алгебраической структурой кодовых комбинаций. Один и таких классов представляют линейные коды, которые, в свою очередь, содержат, различные подклассы кодов, отличающиеся теми или иными свойствами. Некоторые из них позволяют существенно упростить построение кодера и декодера даже при значениях n>100. Оказывается выгодным применять коды с d меньше (оптимального, если их структура позволяет упростить кодирование и особенно декодирование.

При использовании материалов сайта активной гиперссылки обязательна:
http://rateli.ru/ 'Радиотехника'