
5.4. Линейные двоичные блочные коды
(Можно построить и не двоичные линейные коды, если основание m - простое число или степень простого числа, однако это требует более сложного алгебраического аппарата. В настоящее время чаще всего применяют двоичные коды.)
Линейными называются такие двоичные коды, в которых множество всех разрешенных блоков является линейным пространством относительно операции поразрядного сложения по модулю 2. Очевидно, что оно является подпространством линейного пространства, образуемого множеством всех (а не только разрешенных) двоичных последовательностей длины n. Чтобы разрешенные блоки были линейным пространством (см. § 2.5), они должны содержать нулевой элемент, т. е. блок, состоящий из n нулей, должен быть разрешенным, а сумма (подразрядная по модулю 2) любых разрешенных блоков должна быть также разрешенным блоком. Линейные коды называют также групповыми. Двоичный линейный код можно построить следующим образом. Среди всех 2n последовательностей кодовых символов можно выбрать различными способами n линейно-независимых. В частности, ими могут быть (но не обязательно) элементы, образующие ортогональный базис. Выберем из них k любых линейно-независимых блоков, которые обозначим β1, β2,....,βk(k<n), и образуем все линейные комбинации вида
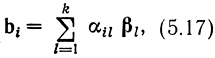
где αil принимает значения 0 или 1, а суммирование - подразрядное по модулю 2. Легко видеть, что множество {bi} этих комбинаций образует линейное пространство, содержащее 2k блоков, т. е. линейный код *.
* (В дальнейшем в этой главе без дополнительных оговорок будем обозначать " + " и "-" поразрядное суммирование по модулю 2.)
Действительно, множество {bi} содержит нулевой элемент, получающийся, когда все αil = 0 (l = 1,..., k). Сумма любых двух элементов
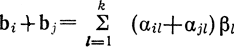
представляет собой также эле
мент этого множества, поскольку αil + αjl принимает значение 0 или 1. Число элементов множества {bi} определяется количеством различных наборов из k двоичных коэффициентов αij, которое, очевидно, равно 2k. Если записать k линейно-независимых блоков, используемых для построения линейного кода, в виде k строк, то получится матрица размером n×k, которую называют порождающей или производящей матрицей кода G.
В общем случае производящая матрица двоичного кода записывается в виде

Здесь bij - двоичный символ (0 или 1), находящийся на j-м разряде i-го кодового слова βi, входящего в выбранный базис.
Полученный таким образом код, содержащий 2k блоков длиной n, обозначают (п, k). При заданных пик существует много различных (n, k) - кодов с различными кодовыми расстояниями d, определяемых различными порождающими матрицами. Все они имеют избыточность χk = 1 - k/n или относительную скорость Rk = k/n.
Заметим, что если две порождающие матрицы различаются только порядком расположения столбцов, то определяемые ими коды являются изоморфными пространствами. Такие коды называют эквивалентными. Они имеют одинаковые кодовые расстояния между соответственными парами кодовых векторов и, следовательно, одинаковые способности обнаруживать и исправлять ошибки.
Чаще всего применяют систематические линейные коды, которые строят следующим образом. Сначала строится простой код длиной k, т. е. множество всех k-последовательностей двоичных символов, называемых информационными. Затем к каждой из этих последовательностей приписывается r = n-k проверочных символов, которые получаются в результате некоторых линейных операций над информационными символами. Можно показать, что для каждого линейного кода существует эквивалентный ему систематический код.
Простейший систематический код (n, n-1) строится добавлением к комбинации из n-1 информационных символов одного проверочного, равного сумме всех информационных символов по модулю 2. Легко видеть, что эта сумма равна нулю, если среди информационных символов содержится четное число единиц, и равна единице, если число единиц среди информационных символов нечетное. После добавления проверочного символа образуются кодовые комбинации, содержащие только чет единиц, т. е. комбинации с четным весом.
Такой код (n, n-1) имеет d = 2, поскольку две новые комбинации, содержащие по четному числу единиц, не могут различаться в одном разряде. Следовательно, он позволяет обнаружить одиночные ошибки. Легко убедиться, что, применяя этот код в схеме декодирования с обнаружением ошибок, можно обнаруживать все ошибки нечетной кратности. Для этого достаточно подсчитать число единиц в принятой комбинации и проверить, является ли оно четным. Если при передаче комбинации произойдут ошибки в нечетном числе разрядов q, то принятая комбинация будет иметь нечетный вес и, следовательно, окажется запрещенной. Такой код называют кодом с одной проверкой на четность.
Обозначим через bi символ кода (0 или 1), стоящий на i-м месте в кодовой комбинации. Тогда для систематического (n, k)- кода общего вида получаем следующее правило построения комбинаций (b1, ..., bk, bk+1, bn); символы b1 ,..., bk выбирают в соответствии с передаваемой информацией, a bi при i>k определяют так, чтобы удовлетворялись условия
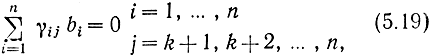
где γij - коэффициенты (0 или 1), характеризующие данный код.
Если набор всех коэффициентов γij собрать в таблицу (матрицу), то получим так называемую проверочную матрицу кода Н размерности n×(n-k):
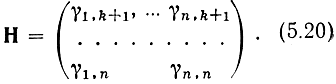
Единицы в каждой j-й строке матрицы Н показывают, какие информационные символы нужно сложить по модулю 2, чтобы получить нуль.
Из (5.19) можно придти к выводу, что произведение порождающей и транспонированной проверочной матриц
Здесь произведение матриц, состоящих из двоичных чисел, понимается в обычном смысле, но с учетом того, что сложения производят по модулю 2. Штрих обозначает транспонирование, а 0 - нулевую матрицу размерности k×(n-k).
Для рассмотренного примера кода (n, n-1) с четным весом проверочная матрица вырождается в вектор-строку длиной n:
а порождающая матрица имеет вид

Рассмотрим другой пример систематического кода - код (7,4) , заданный порождающей матрицей
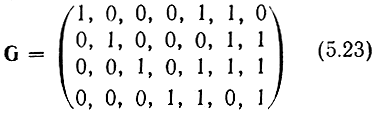
или проверочной матрице
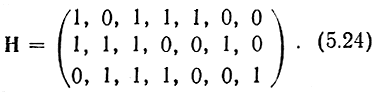
Этот код имеет d = 3 и позволяет обнаруживать все одиночные и двойные ошибки или исправлять (по алгоритму Хэмминга) все одиночные ошибки.
Заметим, что строки проверочной матрицы являются линейно- независимыми векторами. Следовательно, проверочная матрица может служить порождающей для другого линейного кода t(n, n-k), называемого двойственным. Так, например, матрица (5.24) является порождающей матрицей кода (7. 3), имеющего d = 4. Матрица (5.23) является проверочной для этого кода.
Преимуществом линейных, в частности систематических, кодов является то, что в кодере и декодере не нужно хранить список из 2k блоков, а при декодировании не нужно вычислять 2k расстояний. Вместо этого достаточно хранить, например, n-k строк проверочной матрицы и при декодировании проверять выполнение n-k равенств (5.19). Так, например, при коде (100, 50) нужно хранить 50 строк по 100 символов, т. е. всего 5000 символов, а не 1017, как при табличном кодировании, и проверять 50 равенств, вместо перебора 1015 расстояний.
Обнаруживать и исправлять ошибки при систематическом коде можно следующим образом. В режиме обнаружения ошибок проверяют выполнение равенств (5.19) и если хотя бы одно из них не выполнено, принятый блок бракуют как ошибочный. В режиме исправления ошибок после проверки равенства (5.19) "троится последовательность с = (c1, с2, ....,cn-k), называемая синдромом, где cj(j = 1, ..., n-k) -двоичный символ равный нулю, если j-е равенство в (5.19) выполнено, и единице если оно не выполнено. Нулевой синдром указывает на то, что все проверки выполнены, т. е. принятый блок является разрешенным. Всякому ненулевому синдрому соответствует определенная конфигурация ошибок, которая и исправляется. Так, например, для рассмотренного кода (7,4) в табл. 5.1 представлены ненулевые синдромы и соответствующие конфигурации ошибок.

Таблица 5.1
Таким образом, код (7,4) позволяет исправить все одиночные ошибки.
Из этого примера видно, что при декодировании систематического кода не требуется перебирать таблицу, содержащую 2k кодовых комбинаций, и производить n-k сравнений. Помимо тех операций, которые осуществляются в кодере, декодер должен произвести n-k сравнений и перебрать таблицу исправлений, содержащую 2n-k строк. Для такого кода, как (7, 4), это осуществляется просто, но зато код оказывается малоэффективным.
Как неоднократно отмечалось, для получения высокой верности связи следует применять коды с достаточно большой длиной. Однако с ростом n, если отношение k/n (скорость кода) фиксировано, растет и разность n-k, а следовательно, и объем таблицы исправлений, равный 2n-k. Так, для кода (63, 45) он равен 218 = 262 144.
Следовательно, применение систематического кода в общем случае хотя и позволяет упростить декодирование по сравнению с табличным методом, все же при значениях n порядка нескольких десятков не решает задачи практической реализации.
Если (n, k) - код используется для обнаружения ошибок, то в теории кодирования доказывается, что при любой вероятности ошибочного приема символа р≤1/2 найдется код, для которого
Более того, при любых n и k существует код, который в любом двоичном симметричном канале без памяти обеспечивает выполнение неравенства (5.25), какова бы ни была вероятность ошибки р≤1/2. Такие коды называются равномерно обнаруживающими ошибки.
Таким образом, увеличивая число корректирующих символов, можно обеспечить сколь угодно малую вероятность не обнаруженной ошибки (и, следовательно, вероятность выдачи получателю ложной информации). Однако при сохранении скорости кода k/n это потребует увеличения длины блока n. При большой длине блока вероятность появления обнаруживаемой ошибки возрастает и, следовательно, увеличиваются трудности восполнения потерянной информации.
К наиболее простым двоичным систематическим кодам относят коды Хэмминга с d = 3. Для любого натурального числа r существует код Хэмминга при n = 2r-1 и k = n-r. Двойственными кодами к кодам Хэмминга являются эквидистантные коды при n = 2r-1, k = r и d = 2r-1, причем расстояние между любой парой кодовых комбинаций одинаково, чем и обусловлено название кодов. Коды Хэмминга и эквидистантные обладают свойством равномерно обнаруживать ошибки.
Теория помехоустойчивости кодирования достигла больших успехов. Предложен ряд кодов и способов декодирования, при которых сложность декодера растет не экспоненциально, а лишь как некоторая степень n. Более подробно вопросы помехоустойчивого кодирования см. в [1, 9, 12, 20].

При использовании материалов сайта активной гиперссылки обязательна:
http://rateli.ru/ 'Радиотехника'